A walkthrough of six approaches to the split-apply-combine pattern in R, from explicit column-by-column summaries to parallel execution with furrr, using the Palmer Penguins dataset as a running example.
Author
Affiliation
Erwin Lares
Research Cyberinfrastructure (RCI), Division of Information Technology, UW-Madison
Published
May 11, 2026
Modified
July 16, 2026
Abstract
A common challenge in research workflows is applying the same analysis to multiple subsets of a dataset — by species, treatment group, geography, or any other grouping variable. This post walks through six approaches to that problem in R, using descriptive statistics on the Palmer Penguins dataset as a running example. The approaches range from fully explicit, column-by-column code to parallel execution across multiple cores with the furrr package. Along the way, I highlight how the choice of tool reflects a tradeoff between specificity and generality: dplyr’s across() is the right default when the goal is a flat summary table, while map() and future_map() become worthwhile when each subset needs to be treated as an independent unit of analysis that may return something more complex such as models or plots.
1 The problem: one analysis, multiple datasets
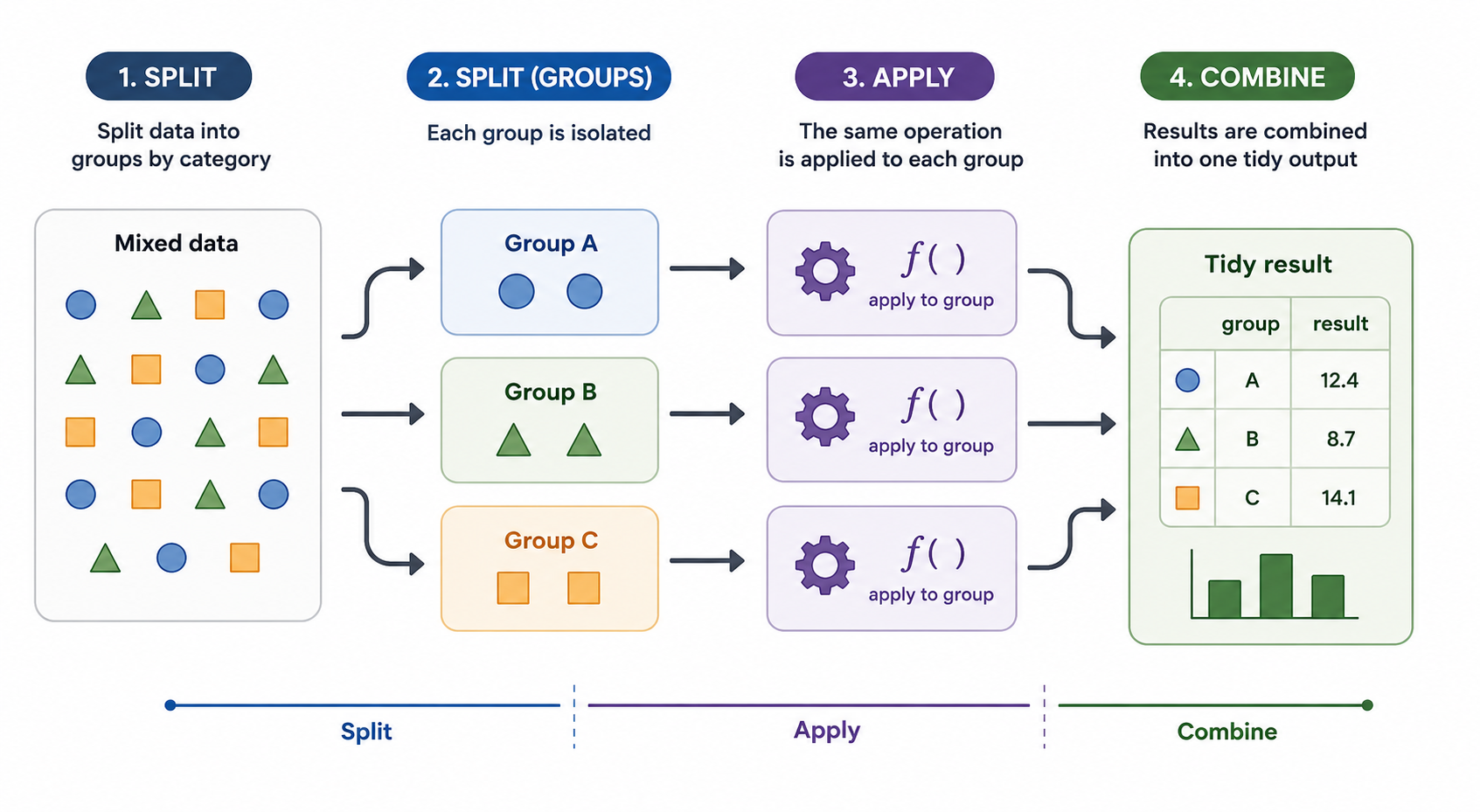
Many research workflows require the same analysis to be repeated across subsets of a larger dataset. We may want to summarize measurements within subsets defined by species, treatment group, geography, or any other grouping variable. In this post, I use the Palmer Penguins dataset to walk through several ways to express this split-apply-combine pattern: split the data into groups, apply the same analysis to each group, and combine the results into a single output.
Split-apply-combine workflow
The examples start with deliberately explicit code, then move through progressively more abstract approaches: for loops, across(), group_modify(), map(), and finally future_map(). Each approach solves the same basic problem, but each emphasizes a different way of thinking about repeated work. The goal is not to argue that every approach is equally appropriate for this particular summary table. Instead, the goal is to show how the same analysis can be reorganized as the workflow becomes more complex, more reusable, or better suited to parallel execution.
The last part of the post explores how to take advantage of the multiple cores available on modern computers. Parallel execution is not always faster, especially for small examples, but the programming pattern is useful when the same analysis must be repeated across many files, groups, simulations, or model-fitting tasks.
2 Input resolution
This function — from toolero, a package developed at RCI for managing execution context across environments — allows one codebase to resolve input files differently depending on how the code is being run. That is useful for avoiding code drift between interactive development, report rendering, and command-line execution.
The logic is straightforward. When you call detect_execution_context(), it returns one of three values: interactive, quarto, or rscript. Knowing the execution context lets the script decide where the input path should come from. In interactive mode, the path can be hardcoded for local development. During Quarto rendering, the path can come from a document parameter. When the code runs from the command line with Rscript, the path can come from a positional command-line argument.
Code
# detect_execution_context() identifies which of three environments this# code is running in: interactive RStudio, quarto render, or Rscript.# Each context resolves the input file path differently.## interactive : you are running chunks in RStudio -- path is hardcoded# to the local data file for development convenience# quarto : document is being rendered -- path comes from params# defined in the YAML header above# rscript : document is running on a remote cluster -- path comes# from the first command line argumentcontext <-detect_execution_context()input_file <-switch(context,interactive ="palmerpenguins.csv",quarto = params$input_file,rscript =commandArgs(trailingOnly =TRUE)[1])penguins <-read_csv(input_file)
3 Tabular results per species
I do not want the analysis itself to distract from the process I want to showcase. For this post, I limit the analysis to a set of descriptive statistics applied to the Palmer Penguins dataset. In short, we want to understand how several body measurements are distributed across species. This gives us a compact example that is simple enough to follow, but rich enough to demonstrate several ways of applying the same analysis to multiple subsets.
The summary statistics include measures of central tendency, range, spread, and selected quantiles for four measurement variables: body mass, flipper length, bill length, and bill depth.
4 Approach 1: Explicit summaries
The first approach writes every calculation separately. This is a deliberately explicit implementation. It is readable in the sense that every output column is spelled out, but it is also verbose, repetitive, easy to mistype, and difficult to maintain as the number of variables or summary functions grows.
The word “explicit” should not be read as a criticism. Explicit code has real value — it is maximally transparent, and in a teaching context that transparency is the point. The weakness is that explicit code does not scale well. Once you add more variables or more summary functions, the code becomes harder to maintain and easier to break.
On my 2024 MacBook Pro, for the extended Penguin dataset consisting of 344 rows and 8 columns, the explicit approach took approximately 2.019 seconds to run.
5 Approach 2: For loops
For loops make the repeated structure of the task visible. Rather than asking dplyr to perform the repetition for us, we can write the repetition ourselves. This is not necessarily the most concise or idiomatic way to solve the problem in R, but it is useful for understanding what grouped summaries are doing: they repeat the same operation over smaller pieces of a larger dataset.
5.1 Approach 2.1: Looping over species
A loop over species makes the grouping logic explicit. For each species, we filter the data, compute one row of summaries, store that row in a list, and then bind the results together.
On my machine, the for loop over species took approximately 2.362 seconds.
5.2 Approach 2.2: Looping over functions
A loop over functions abstracts a different dimension of the problem. Instead of writing mean(), min(), max(), sd(), and the other functions repeatedly by hand, we store the functions in a list and apply each one systematically. The grouping by species is still handled by dplyr.
On my machine, the loop over functions took approximately 3.188 seconds.
5.3 Approach 2.3: Looping over species, functions, and variables
The nested-loop version makes the full computational structure visible. For each species, for each summary function, and for each measurement variable, the code calculates one value and stores it in a named output column.
for loop over species and functions: 0.029 sec elapsed
On my machine, the nested loop over species, functions, and variables took approximately 2.466 seconds.
The explicit approach emphasizes readability by spelling everything out. The for-loop approaches emphasize the repeated structure of the computation. Looping over species highlights the grouping logic, looping over functions highlights the reusable summary operations, and looping over species, functions, and variables exposes the full grid of operations being performed. For production code, however, these loop-based versions require more bookkeeping than necessary for a simple grouped summary.
6 Approach 3: Declarative summaries with across()
The across() approach is the recommended default for this example because the desired output is a tibble of scalar summaries. Instead of listing every computation manually, we declare the measurement columns and the summary functions, then let summarize() generate the combinations. This version is shorter, easier to maintain, and easier to scale up than the explicit or loop-based alternatives.
On my machine, for the extended Penguin dataset consisting of 344 rows and 8 columns, the declarative across() approach took approximately 2.059 seconds to run. In this run, it was fractionally slower than the fully explicit version, but it is easier to read, easier to maintain, and easier to extend. Adding or removing a calculation requires changing the function list, not rewriting the entire summary.
7 Approach 4: Per-group data-frame workflows with group_modify()
After writing the summaries explicitly and then refactoring them with across(), we can take one more step toward a reusable split-apply-combine workflow with group_modify(). The explicit version lists every calculation one by one, while the across() version declares a set of columns and a set of functions to apply inside summarize(). group_modify() shifts the focus from applying functions across columns to applying a function across groups.
For each group, dplyr passes two objects to the function: .x, the subset of rows for that group, and .y, a one-row tibble containing the group key. Because the function must return a data frame, group_modify() is best suited for cases where each group needs a custom “data frame in, data frame out” analysis that is more involved than a standard summarize() call.
On my machine, the group_modify() approach took approximately 2.262 seconds for the same dataset. In this example, it is slower than the simpler across() approach, and it does not provide much practical benefit because the output is still a straightforward summary table.
The reason to consider group_modify() is not speed. The main motivation is flexibility. summarize() is best suited for reducing each group to one row of scalar summaries. When each group needs to return a more complex data frame, group_modify() becomes a better fit. As a rule of thumb, use group_modify() when each group needs to go through a custom mini-pipeline and return a data frame.
8 Approach 5: Split-apply-combine workflows with map()
The fifth approach uses map() to make the split-apply-combine pattern explicit. Instead of asking dplyr to keep the grouped workflow intact, we first split the data into separate pieces and then apply the same analysis function to each piece. In this example, each species becomes its own small data frame, and the same summary function is applied to each species-level subset.
This approach is more general than the previous ones, but it is not the most direct tool for this particular summary task. If all we need is one summary table with one row per species, group_by() plus summarize() plus across() is clearer and more idiomatic. Here, the purpose of introducing map() is not to make the code shorter. The purpose is to show a workflow pattern that becomes useful when each subset should be treated as an independent unit of analysis.
The structure of the workflow is:
Define a function that analyzes one subset of the data.
On my machine, using map() took approximately 14% longer than the explicit approach for this summary task. That result is not surprising. For simple grouped summaries, map() adds machinery that dplyr does not need. The value of this approach appears when the per-subset analysis becomes more substantial than a scalar summary table.
9 Why bother with map()?
The strongest case for map() is that it lets us abstract an analysis. We can write one function that knows how to analyze one input, test that function on a single subset, and then apply it to many inputs. This separation between the analysis logic and the iteration logic makes the workflow easier to test, debug, and reuse.
This abstraction matters when the output is more complex than a tibble of scalar summaries. Each subset might produce a model, a plot, a diagnostic table, a saved file, or a list of related outputs. Those outputs do not always fit neatly inside a single summarize() call, but they fit naturally into a map() workflow because map() can return lists or list-columns.
The same pattern also works well for file-based workflows. Instead of splitting one data frame into groups, we might start with a vector of file paths. Each file path can be mapped to a function that reads the file, analyzes it, and returns or saves the result. That pattern closely resembles how batch jobs and cluster workflows are often organized: one input, one analysis, one output.
Finally, map() prepares the code for parallel execution. Once the workflow is organized as “one input, one function, one result,” moving from map() to furrr::future_map() is a relatively small conceptual step. That makes map() a useful bridge from local sequential work to local multicore work.
10 Approach 6: Parallel split-apply-combine with future_map()
The final approach uses the future and furrr packages to run the split-apply-combine workflow in parallel. The refactor is conceptually simple: define a function that summarizes one subset, split the data into subsets, and use future_map_dfr() to apply the function across those subsets.
Using multiple cores means allowing more than one R process to work at the same time. In a regular map() workflow, each subset is processed sequentially: R finishes the first subset, then moves to the second, then the third, and so on. In a future_map() workflow, those subset-level tasks can be distributed across multiple workers. A worker is an independent R session that can carry out one piece of the computation.
The number of workers should be chosen intentionally. More workers does not automatically mean faster code. Each worker has startup costs, memory costs, and communication costs. R may need to launch separate sessions, copy data and functions to those sessions, and collect the results when the jobs finish. If the individual jobs are small, that overhead can dominate the actual computation.
For this example, the unit of work is the species-level subset. Because the Palmer Penguins data have three species, we effectively have three independent jobs: one for Adelie, one for Chinstrap, and one for Gentoo. Using three workers matches the structure of the problem naturally. Each worker can take one species-level subset, run the same summary function, and return the result.
On my machine, using three workers took approximately 6.4 seconds. By contrast, using nine workers did not make the job faster. In fact, the same task took approximately 9.468 seconds with nine workers. That result is a useful reminder that parallel execution is not just about using as many cores as possible. The number of workers should reflect the number of independent tasks, the size of those tasks, and the overhead required to coordinate them.
For this exact summary task, the data are small enough and the per-species calculations are short enough that parallelization is not necessarily faster than the non-parallel approaches. The pattern is still useful because it is the same pattern you would use for larger workflows that train models, run simulations, process many files, or execute longer analyses independently across data chunks.
When moving from map() to future_map(), the line-level change is small, but the surrounding execution environment matters. You need a future plan, a deliberate number of workers, a strategy for random-number generation if the analysis uses randomness, and enough care to avoid moving unnecessarily large objects to each worker. In this example, furrr_options(seed = TRUE) is included to make random-number generation parallel-safe if randomness is introduced later.
11 Timing summary
The table below collects the wall-clock times for each approach on the same dataset. These numbers are illustrative and machine-specific. All measurements were taken on a 2024 MacBook Pro with an M4 chip, 48GB of memory, running macOS Tahoe 26.5. Your results will differ, but the relative ordering is likely to be informative regardless of hardware.
Approach
Time (s)1
± vs Approach 1 (s)
± vs Approach 1 (%)
Best suited for
1: Explicit summaries
2.019
0.000
0.00
Teaching and one-off analyses where every calculation should be visible and nothing is hidden behind abstraction. Easy to read, hard to maintain at scale.
2: For loops
2.362
0.343
17.00
Demonstrating what grouped summaries are doing under the hood. Useful for building intuition about iteration, less useful for production code.
3: Declarative summaries with across()
2.059
0.040
1.98
The recommended default for grouped scalar summaries. Compact, maintainable, and idiomatic. Adding or removing a statistic requires editing a list, not rewriting a block.
4: Per-group workflows with group_modify()
2.262
0.243
12.03
Cases where each group needs a custom mini-pipeline that returns a data frame more complex than a row of scalar summaries.
5: Split-apply-combine with map()
2.300
0.281
13.92
Workflows where each subset is an independent unit of analysis, especially when the output may be a model, a plot, a file, or a list rather than a flat tibble.
6: Parallel execution with future_map()
6.400
4.381
217.00
Large-scale workflows with many independent inputs: many files, many simulations, many model fits. Overhead dominates for small tasks like this one.
1 Measured on a 2024 MacBook Pro, M4 chip, 48GB RAM, macOS Tahoe 26.5. The future_map() time reflects 3-worker multisession overhead on a small dataset; for larger workloads the relationship inverts.
The clearest takeaway from the timing data is that for this particular task — scalar grouped summaries on a moderately sized dataset — the differences among Approaches 1 through 4 are small enough to be practically irrelevant. The choice among them should be driven by readability and maintainability, not speed. The map() and future_map() approaches carry overhead that only pays off when the per-subset work is substantial enough to justify the cost of splitting, distributing, and collecting results.
12 Recommended approach: knowing when to reach for which tool
The six approaches in this post converge on the same result, but they reflect meaningfully different assumptions about the shape of the problem. Before closing, it is worth being explicit about the decision point that separates them.
across() inside a summarize() call is the right tool when the goal is a flat tibble with one row per group and scalar values in every cell. This is the case for most descriptive summary tables: means, standard deviations, quantiles, counts. dplyr is optimized for exactly this pattern, and across() expresses it concisely. The return object is predictable — a tibble with a fixed shape that is easy to print, save, or pass downstream.
map() and future_map() are the right tools when that assumption breaks down. If each subset needs to return something other than a row of scalars — a fitted model, a diagnostic plot, a list of outputs, a saved file — then summarize() is no longer the right container, and map() steps in. The return object from a map() call is a list, which can hold anything: tibbles of different shapes, model objects, ggplot objects, or nested structures. That generality is precisely what makes map() more powerful and also slightly heavier than across().
In other words, the decision point is the shape of the output. If each group produces one row, reach for across(). If each group produces something else — or something you are not sure about yet — reach for map(). And if those per-group tasks are large enough and independent enough that running them sequentially feels wasteful, reach for future_map() and let your laptop’s cores share the load.